
How AI is Advancing Facial Recognition Accuracy
Picture an airport security checkpoint late at night. Lighting is poor, cameras are aging, and queues grow as staff deal with false alerts. Today, the same cameras powered by AI-driven facial recognition can identify individuals correctly in low light and at awkward angles, reducing delays and improving security.
This leap is no accident. Deep learning, data engineering and rigorous evaluation standards have transformed how machines “see” and compare faces. Advances like FaceNet’s embedding approach and ArcFace’s angular margin loss have driven steady gains in real-world performance across demographics.
In this article, we unpack how AI improves facial recognition accuracy. You will learn about the building blocks behind today’s systems, the techniques that reduce errors in the field and the best practices that ensure reliable, responsible deployment.
Key Takeaways
- AI has transformed face recognition accuracy through deep embeddings, margin losses, and transformer backbones.
- Robustness techniques like multi-view training, 3D modelling, and occlusion-aware networks reduce errors in challenging conditions.
- Data diversity and synthetic augmentation are critical to reduce bias and improve real-world performance.
- Deployment factors – camera quality, edge vs. cloud decisions, and ongoing model monitoring, directly impact success.
- Privacy and transparency should be built into every stage, from template security to explainable thresholds.
From Templates to Transformers: A Short History
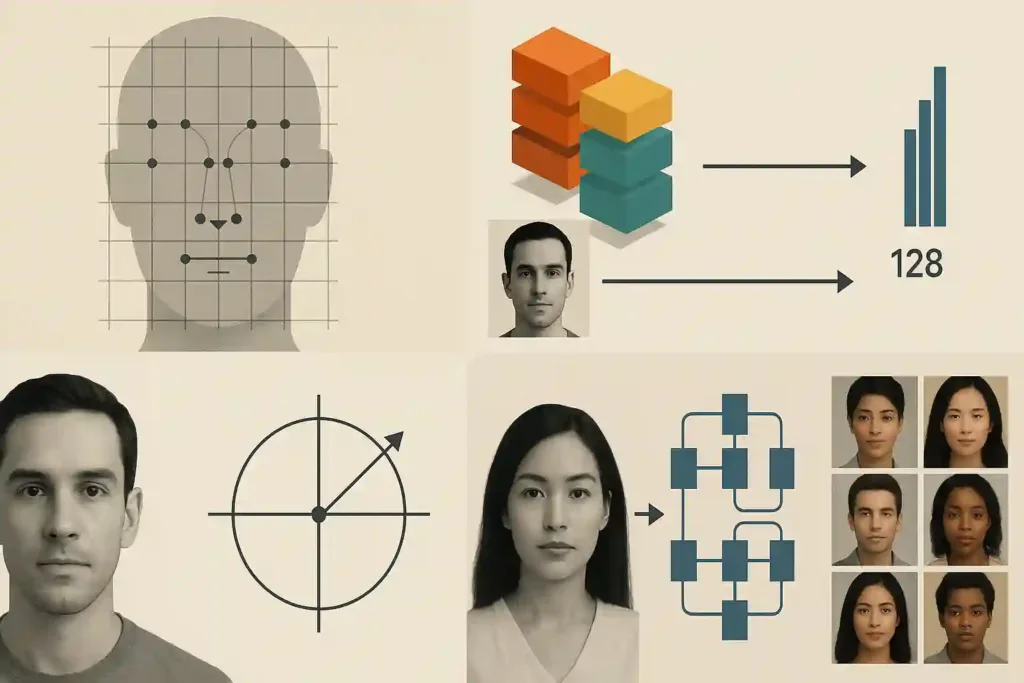
Facial recognition began with template matching and handcrafted features such as Eigenfaces and Local Binary Patterns (LBP). These early methods compared pixel intensities across grids of facial landmarks but struggled with changes in lighting, pose and expression.
A breakthrough arrived in 2015 with Google’s FaceNet, which trained a convolutional neural network to map each face into a compact 128-dimensional vector. Optimising for similarity in this embedding space made verification and identification far more robust across conditions.
In 2019, ArcFace introduced angular margin loss, further increasing the separation between identities and boosting real-world accuracy. Today’s systems build on these foundations using transformer architectures, self-supervised learning and synthetic data, enabling models to handle massive, diverse datasets and generalise better across demographics.
The Accuracy Problem: What “Accuracy” Really Means

Accuracy in facial recognition has many dimensions.
Verification (1:1 Matching)
Compares one face against another to confirm an identity. Key metrics:
- False Match Rate (FMR): How often two different people are mistakenly matched.
- False Non-Match Rate (FNMR): How often the same person fails to match.
Identification (1:N Search)
Compares one face against a gallery of many. Key metrics:
- Rank-1 Accuracy: The correct match appears first.
- Top-k Accuracy: The correct match appears within the top k candidates.
Evaluation Curves
Such as ROC and AUC show how well a system balances sensitivity and specificity across thresholds.
Operational constraints
Camera quality, pose variation, lighting, occlusion, demographic variance and gallery size all affect results. Even the best model underperforms if inputs are poor.
Benchmarks such as NIST FRVT
Provide independent, repeatable measures of progress and demographic effects, and are the most cited references for procurement decisions.
Core AI Advances That Drive Higher Accuracy
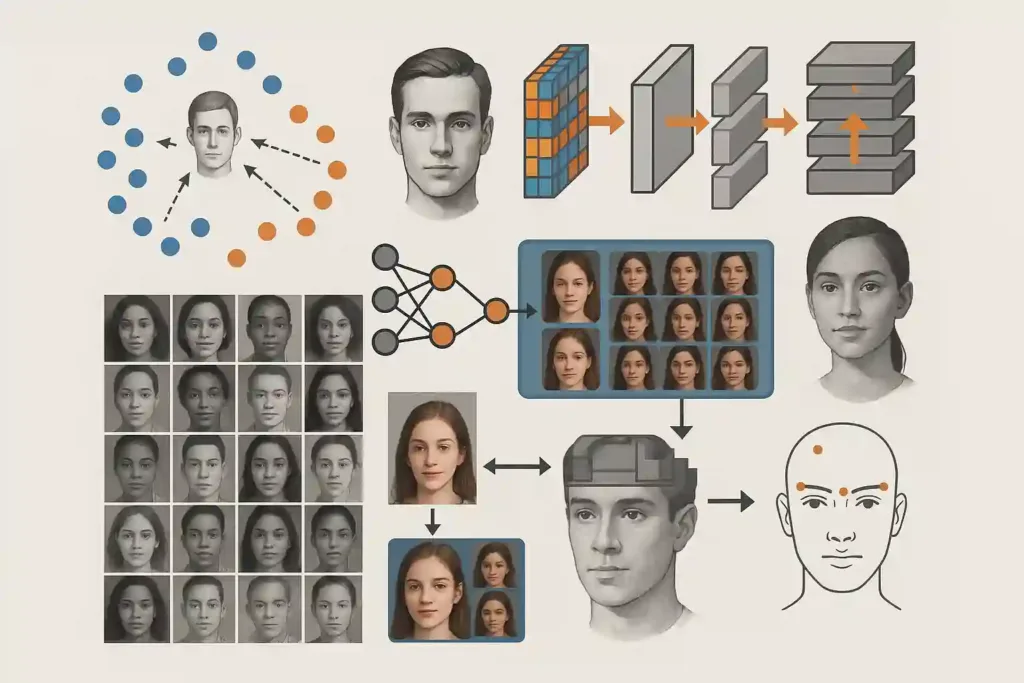
Better Feature Learning and Embeddings
Modern systems use deep CNNs to produce embeddings, or compact numerical representations of faces. Faces of the same person cluster together, while different people are pushed apart.
FaceNet pioneered this approach with triplet loss. ArcFace added angular margin loss to widen gaps between identities while tightening clusters, which increases discrimination power and reduces false matches.
Network Architectures and Scaling
Architectures have evolved from shallow CNNs to deep ResNet-style networks, then to Vision Transformers and hybrids. Transformers capture long-range dependencies and subtle textures, making them more resilient to low-resolution or off-angle images.
Edge deployments may prefer lightweight CNNs for latency and power reasons, while server-side deployments can run larger transformer backbones for maximum accuracy.
Training Strategies for Robustness
Large supervised datasets spanning demographics, poses and lighting conditions are critical. Self-supervised and contrastive learning help extract useful features from unlabelled data. Curriculum learning, hard-example mining and strong augmentation pipelines improve generalisation.
Data Diversity, Augmentation and Synthetic Data
Balanced datasets reduce bias. NIST FRVT consistently shows demographic effects unless datasets are representative. When real data is scarce, synthetic generation using GANs, diffusion models and 3D rendering can fill gaps and stress-test models.
Preprocessing and Normalisation
Detection, alignment, frontalization and illumination normalisation standardise inputs before feature extraction. Quality assessment filters out low-grade images to reduce false results.
Post-processing and Calibration
Score normalisation, adaptive thresholds, multi-frame fusion and temporal smoothing all improve stability. Combining several frames or views of the same individual can significantly outperform single-image comparisons.
Together these advances create the dramatic accuracy improvements seen in today’s best systems.
Also read: Facial Recognition System: Technology, Applications, and AI-Driven Innovation
Robustness: Handling Pose, Occlusion, Aging and Low-Quality Images
Real-world conditions rarely produce perfect inputs. Modern systems counter this through:
- Multi-view training on varied angles and poses.
- 3D Morphable Models (3DMM) to reconstruct faces in three dimensions and rotate them back to frontal view.
- Attention mechanisms and occlusion-aware loss that focus on visible regions instead of being skewed by missing pixels.
- Temporal and multi-camera aggregation to average embeddings across frames, reducing the impact of blur or partial views.
Deployment Considerations that Affect Accuracy
Even the best model fails if deployed poorly. Key factors:
- Camera placement and optics. Distance, resolution and angle determine input quality. High-quality lenses and sensors can improve accuracy more than an incremental model upgrade.
- Edge vs cloud inference trade-offs. Edge processing reduces latency and improves privacy but often uses compressed models. Cloud inference enables larger architectures but introduces latency and regulatory considerations. Hybrid approaches can balance both.
- Continuous monitoring. Conditions evolve over time. Drift detection, periodic fine-tuning and A/B testing ensure systems stay accurate.
Best Practices Checklist
- Curate diverse training sets across age groups, skin tones, genders and geographies.
- Use multi-frame or multi-view aggregation, especially for CCTV or body-worn cameras.
- Validate on your actual operational environment, not only standard benchmarks.
- Set explainable, reproducible thresholds and log decision context for audits.
- Maintain privacy controls by storing embeddings rather than raw images, encrypting data and complying with local regulations.
These practices bridge the gap between lab accuracy and trusted real-world performance.
Conclusion: AI is Redefining Facial Recognition Accuracy
Facial recognition has evolved from brittle, rule-based systems to robust AI-driven capabilities that work across lighting, pose and demographic variation. Deep learning, transformer architectures, large-scale and synthetic data have pushed accuracy to unprecedented levels.
Real-world success, however, depends on disciplined deployment. Data quality, diversity, monitoring and ethical safeguards ensure fairness and trust. Accuracy and accountability must go hand in hand.
Innefu Labs’ AI Vision platform brings together advanced face analytics, multi-camera fusion and privacy-by-design safeguards to deliver high-accuracy recognition at scale.
Learn more about Innefu’s AI Vision platform.
Talk to our team about deploying cutting-edge Facial Recognition System.
By combining the right technology with best practices, your organisation can achieve high-accuracy facial recognition that supports both security and public confidence.
FAQs – Frequently Asked Questions
How does AI improve facial recognition accuracy?
By using deep learning models to extract detailed facial embeddings, handle variations in pose and lighting and combine multiple frames for reliable matching.
What role does training data play?
Diverse, high-quality data including synthetic images helps models generalise across demographics, age groups and conditions.
Can AI facial recognition work in low light or with masks?
Yes. Preprocessing, 3D modelling and attention mechanisms focus on visible regions, improving robustness under difficult conditions.
What metrics measure accuracy?
False Match Rate, False Non-Match Rate, Rank-1 and Top-k identification accuracy and ROC/AUC curves. NIST FRVT benchmarks these at scale.
How can organisations ensure fairness and privacy?
By curating diverse datasets, auditing performance, using explainable thresholds and storing embeddings instead of raw faces.
How does Innefu Labs support high-accuracy facial recognition?
Innefu’s AI Vision platform integrates advanced face analytics, multi-camera fusion and privacy safeguards to deliver reliable and responsible recognition at scale.




